Random Forest Karar Ağacı Algoritması Nedir? (Random Forest Algorithm)
Makine öğrenmesi algoritmaları günümüzde birçok alanda kullanılmaktadır. Bu algoritmalar, birçok uygulama ve veri analizi için kritik öneme sahiptir. Bu algoritmaların arasında, Random Forest algoritması, sınıflandırma, regresyon ve diğer veri analizi problemlerini çözmek için kullanılan popüler bir algoritmadır. Bu makalede, Random Forest algoritması hakkında detaylı bir inceleme yapacağız.
Random Forest Nedir?
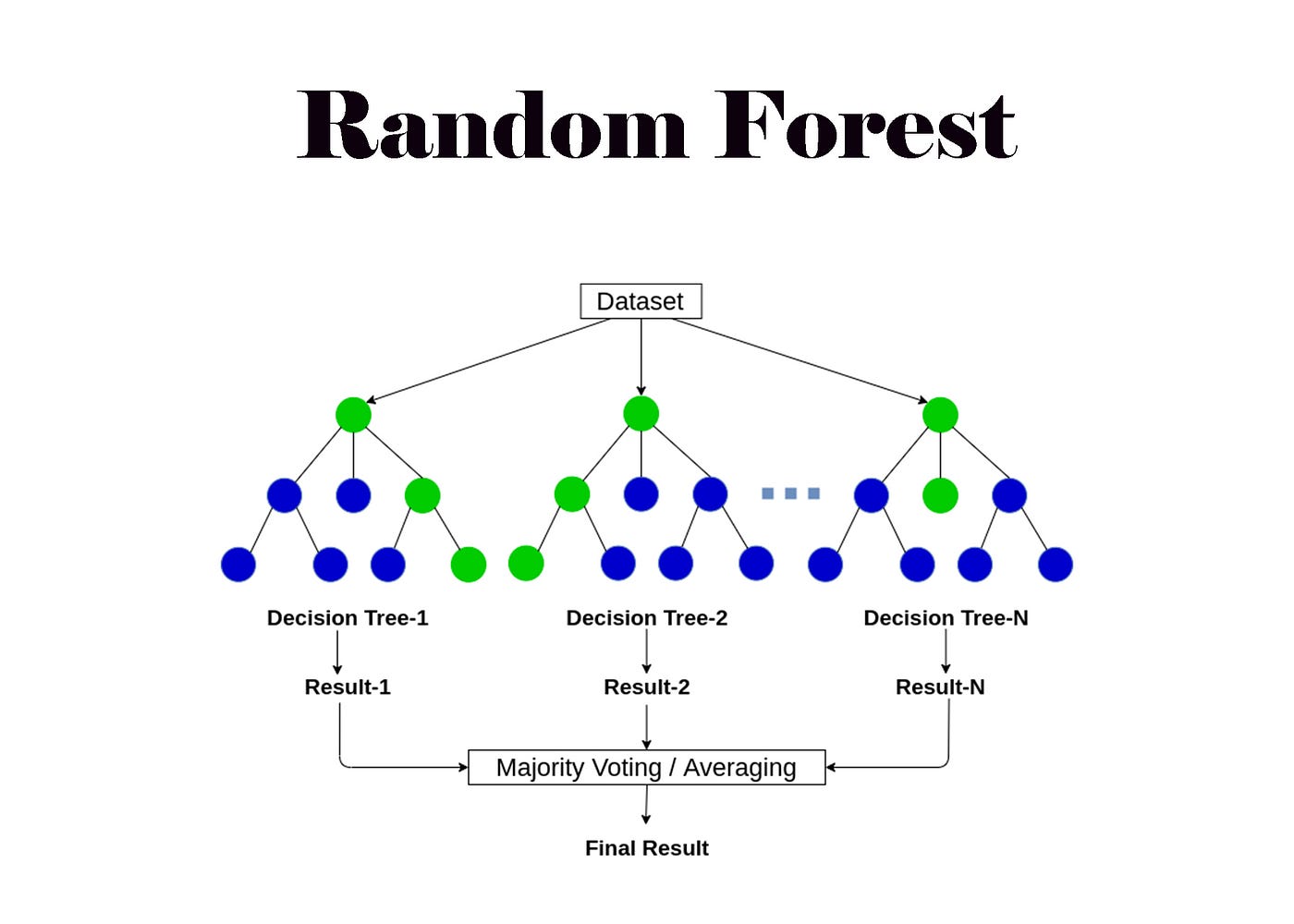
Random Forest, çeşitli ağaçlar oluşturarak ve bu ağaçların sonuçlarını bir araya getirerek tahminler yapmak için kullanılan bir makine öğrenmesi algoritmasıdır. Her bir ağaç, belirli bir özellik alt kümesini kullanarak eğitilir ve birbirinden bağımsızdır. Bu nedenle, Random Forest, hem değişkenler arasındaki etkileşimleri hem de veri setindeki gürültüyü azaltarak, yüksek kaliteli tahminler yapabilir.
Random Forest algoritması, karar ağacı algoritmasından türetilmiştir. Ancak, Random Forest algoritması, tek bir ağaçtan ziyade birden çok ağaç kullanır. Her bir ağaç, bağımsız bir şekilde özellikleri analiz ederek ve bağımlı değişkenlerin özelliklerini en iyi şekilde tahmin etmek için kullanılır. Random Forest, bu ağaçların son sonuçlarını birleştirerek bir tahmin yapar. Bu tahmin, sınıflandırma veya regresyon gibi belirli bir probleme bağlı olarak değişebilir.
Random Forest algoritması, aşağıdaki adımlardan oluşur:
- Rastgele alt örneklem alma: Veri setinin bir alt kümesi rastgele seçilir ve her bir ağaç bu alt kümeden örnekler kullanır.
- Rastgele özellik seçimi: Her bir ağaç, belirli bir özellik alt kümesini kullanarak eğitilir. Bu özellikler, tüm özellikler arasından rastgele seçilir.
- Ağaç oluşturma: Her bir ağaç, veri setinin alt kümesi ve rastgele seçilmiş özellikler kullanılarak oluşturulur. Ağaç, karar düğümleri ve yaprak düğümleri şeklinde oluşur. Karar düğümleri, bir özelliğin bir eşik değerine göre ikiye ayrılmasını içerir. Yaprak düğümleri, sonuçları içerir.
- Tahmin yapma: Tüm ağaçların sonuçları bir araya getirilir ve son tahmin yapılır.
Random Forest, birçok avantaja sahiptir. İlk olarak, bu algoritma, veri setindeki gürültüyü azaltarak daha doğru tahminler yapabilir. İkincisi, ağaçlar arasında özelliklerin yeniden kullanılması, her bir ağacın diğerlerinden farklı özellikleri analiz etmesine ve daha iyi sonuçlar elde etmesine olanak tanır. Üçüncü olarak, Random Forest, aşırı uyum (overfitting) sorununu en aza indirir. Bu, her bir ağacın yalnızca veri setinin alt kümesi üzerinde eğitilmesi ve farklı özellikler kullanması nedeniyle gerçekleşir.

Random Forest algoritması, sınıflandırma ve regresyon gibi birçok farklı veri analizi probleminde kullanılabilir. Sınıflandırma problemlerinde, algoritma, bir veri örneğini belirli bir sınıfa atamak için kullanılır. Örneğin, bir kişinin bir hastalığa sahip olup olmadığını belirlemek için kullanılabilir. Regresyon problemlerinde, algoritma, belirli bir bağımlı değişkenin değerini tahmin etmek için kullanılır. Örneğin, bir evin fiyatını tahmin etmek için kullanılabilir.
Random Forest, birçok açıdan diğer makine öğrenmesi algoritmalarından üstündür. Ancak, bu algoritmanın dezavantajları da vardır. Öncelikle, Random Forest, bazı diğer algoritmalar gibi, parametre ayarlamayı gerektirir.
Özellikle, ağaç sayısı, alt küme boyutu ve özellik seçimi gibi parametrelerin ayarlanması gerekebilir. İkincisi, Random Forest, büyük veri setlerinde bazen yavaş çalışabilir. Üçüncüsü, algoritmanın çıktısı bazen zor yorumlanabilir olabilir.
Bununla birlikte, bu dezavantajlar, Random Forest’un genellikle doğruluğu ve esnekliği nedeniyle yine de tercih edilen bir algoritma haline gelmesini engellemez.
Sonuç olarak, Random Forest, makine öğrenmesi alanında oldukça popüler bir algoritmadır. Bu algoritma, birçok sınıflandırma ve regresyon probleminde kullanılabilir ve birçok avantajı vardır. Özellikle, aşırı uyumu önleme, veri setindeki gürültüyü azaltma ve doğruluğu artırma gibi avantajlara sahiptir. Ancak, bu algoritmanın bazı dezavantajları da vardır ve parametre ayarlamayı gerektirebilir. Random Forest’un popülerliği, veri bilimcilerin veri analizi yaparken tercih ettiği bir algoritma haline gelmesini sağlamaktadır.
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# iris veri setini yükle
iris = load_iris()
# özellikleri ve hedef sınıfı ayır
X = iris.data
y = iris.target
# verileri eğitim ve test kümeleri olarak ayır
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Random Forest modelini oluştur
random_forest = RandomForestClassifier(n_estimators=100)
# Modeli eğit
random_forest.fit(X_train, y_train)
# Test seti üzerinde modelin doğruluğunu ölç
y_pred = random_forest.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Bu örnek kod, öncelikle iris veri setini yükler ve özellikleri ve hedef sınıfı ayırır. Daha sonra, verileri eğitim ve test kümeleri olarak ayırır. Ardından, Random Forest modelini oluşturur ve eğitir. Son olarak, test seti üzerinde modelin doğruluğunu ölçer.
RandomForestClassifier sınıfı, birçok parametreyle yapılandırılabilir. Bunların arasında ağaç sayısı, özellik seçimi ve öznitelik sayısı yer alır. Örneğin, n_estimators parametresi, oluşturulacak ağaç sayısını belirler. Default değeri 100'dür. max_depth parametresi ise ağaçların maksimum derinliğini belirler.
Bu örnek kod, scikit-learn kütüphanesi kullanarak basit bir Random Forest uygulaması gösterir. Ancak, gerçek dünya veri setlerinde, daha kapsamlı bir değerlendirme ve hata ayıklama işlemi gerekebilir.
Random Forest algoritması, birçok uygulama alanında kullanılmaktadır. Bu algoritmanın kullanıldığı bazı popüler uygulama alanları aşağıda açıklanmaktadır.
- Sınıflandırma: Random Forest algoritması, sınıflandırma problemlerinde başarılı sonuçlar verir. Örneğin, bir resim sınıflandırma probleminde, Random Forest algoritması, belirli bir resmin hangi sınıfa ait olduğunu tahmin edebilir.
- Öznitelik Seçimi: Random Forest algoritması, öznitelik seçimi için de kullanılabilir. Bu algoritma, veri setindeki her özniteliğin önemini hesaplayabilir ve en önemli öznitelikleri seçebilir. Bu öznitelik seçimi, gereksiz öznitelikleri kaldırarak, modelin doğruluğunu artırabilir.
- Hasta Tanımlama: Random Forest algoritması, tıp alanında da kullanılır. Örneğin, bir hastanın belirli bir hastalığa sahip olup olmadığını tahmin etmek için kullanılabilir. Bu uygulama, doktorların teşhis sürecinde yardımcı olabilir.
- Finans: Random Forest algoritması, finansal analiz için kullanılabilir. Bu algoritma, finansal verileri analiz edebilir ve hisse senedi fiyatları gibi finansal değişkenleri tahmin edebilir.
- Pazarlama: Random Forest algoritması, pazarlama alanında da kullanılabilir. Örneğin, bir müşterinin belirli bir ürünü satın alma olasılığını tahmin etmek için kullanılabilir. Bu uygulama, pazarlama kampanyalarının etkililiğini artırabilir.
- Görüntü İşleme: Random Forest algoritması, görüntü işleme alanında da kullanılabilir. Örneğin, bir görüntünün parçası olan belirli bir nesnenin sınıflandırılması için kullanılabilir. Bu uygulama, örneğin trafik işaretlerinin otomatik tanınması için kullanılabilir.
- E-Posta Spam Filtreleme: Random Forest algoritması, e-posta spam filtreleme için kullanılabilir. Bu algoritma, belirli bir e-postanın spam olup olmadığını tahmin edebilir. Bu uygulama, spam e-postaların azaltılmasına yardımcı olabilir.
Random Forest algoritması, yukarıda bahsedilen alanlar dışında da birçok uygulama alanında kullanılmaktadır. Bu algoritmanın kullanımı, veri analizinde büyük bir rol oynar ve daha doğru sonuçlar elde edilmesini sağlar.
Random Forest algoritması, yüksek doğruluk oranları ile bilinen popüler bir topluluk öğrenme algoritmasıdır. Ancak, her algoritmanın olduğu gibi, Random Forest algoritmasının da bazı dezavantajları vardır. Bu dezavantajlar aşağıda açıklanmaktadır.
- Yavaş İşlem Süresi: Random Forest algoritması, birçok karar ağacını bir araya getirerek bir topluluk öğrenme modeli oluşturur. Bu nedenle, model eğitimi ve tahmin işlemleri oldukça zaman alabilir. Özellikle büyük veri kümeleri için, işlem süresi oldukça yavaş olabilir.
- Bellek Sorunları: Random Forest algoritması, birçok karar ağacını bir araya getirerek bir topluluk öğrenme modeli oluşturduğundan, bellek sorunları yaşanabilir. Özellikle büyük veri kümeleri için, bellek sorunları daha da belirgin hale gelebilir.
- Yüksek Boyutluluk: Random Forest algoritması, yüksek boyutlu veri kümeleri için uygulanabilir olsa da, yüksek boyutlu veri kümelerinde doğruluk oranları düşük olabilir. Bu nedenle, yüksek boyutlu veri kümelerinde, Random Forest algoritması kullanılması yerine, boyut azaltma teknikleri kullanılabilir.
- Öznitelik Seçimi Sorunları: Random Forest algoritması, öznitelik seçimi sorunlarına neden olabilir. Özellikle, yüksek boyutlu veri kümelerinde, modelde kullanılan özniteliklerin belirlenmesi zor olabilir. Bu nedenle, model eğitiminde yanlış özniteliklerin kullanılması, modelin doğruluğunu etkileyebilir.
- Aşırı Uyumluluk Sorunu: Random Forest algoritması, eğitim verilerine aşırı uyumlu hale gelebilir. Bu, modelin doğru tahminler yapmak yerine, eğitim verilerine aşırı uyum sağlamasına neden olabilir. Bu sorun, genelleme performansını etkileyebilir.
- Karar Ağacı Sayısı Sorunu: Random Forest algoritması, topluluk öğrenme modeli için kullanılacak karar ağacı sayısının belirlenmesi sorunu ile karşı karşıya kalabilir. Karar ağacı sayısı ne kadar az ise, model daha hızlı olacak ancak doğruluk oranı düşük olabilir. Karar ağacı sayısı ne kadar fazla ise, model daha doğru olacak ancak daha yavaş olabilir.
- Eğitim Verilerindeki Dengesizlik Sorunu: Random Forest algoritması, eğitim verilerindeki dengesizlik sorunuyla da karşı karşıya kalabilir. Eğitim verilerindeki bir sınıf yeterince temsil edilmiyorsa, model bu sınıfı doğru bir şekilde öğrenemeyebilir. Bu durumda, model doğru tahminler yaparken, öğrenilmeyen sınıf için hatalı tahminler yapabilir.
- Veriye Bağımlı Sonuçlar: Random Forest algoritması, veri kümesindeki değişkenlere ve özelliklere bağlı olarak sonuçları etkileyebilir. Veri kümesindeki değişkenlerin ve özelliklerin değişmesi, modelin doğruluğunu etkileyebilir.
- Yüksek Duyarlılık: Random Forest algoritması, özellikle küçük veri kümeleri için yüksek duyarlılık gösterir. Küçük veri kümelerinde, veri kümesindeki tek bir örnek bile, modelin doğruluğunu etkileyebilir.
Peki Avantajları Neler?
- Yüksek Doğruluk: Random Forest algoritması, sınıflandırma ve regresyon problemlerinde yüksek doğruluk oranları sağlayan bir algoritmadır. Bu, modelin karmaşıklığına ve boyutuna bağlı olarak değişebilir, ancak genellikle yüksek doğruluk oranları elde edilir.
- Esneklik: Random Forest algoritması, sınıflandırma ve regresyon problemlerinin yanı sıra, çoklu sınıf, çoklu etiket ve çoklu çıkış problemlerini de ele alabilir. Ayrıca, algoritma, sayısal ve kategorik verileri kabul eder ve verilerin özelliklerine bağlı olarak uygun modeli oluşturabilir.
- Yüksek Performans: Random Forest algoritması, büyük veri kümeleri üzerinde hızlı ve yüksek performanslı bir şekilde çalışabilir. Algoritmanın paralelleştirilmesi, işlem süresini azaltabilir ve büyük veri kümelerinde kullanılabilirliği artırabilir.
- Özellik Seçimi: Random Forest algoritması, veri kümesindeki en önemli özellikleri otomatik olarak seçebilir. Bu, veri kümesindeki en yararlı özellikleri seçerek modelin doğruluğunu artırabilir.
- Çoklu Karar Ağaçları: Random Forest algoritması, birden fazla karar ağacını bir araya getirerek bir model oluşturur. Bu, her ağacın veri kümesinin farklı bölümlerini ele aldığı ve sonuçları bir araya getirdiği anlamına gelir. Bu, bir karar ağacının kendi başına yapabileceğinden daha doğru bir sonuç elde edilmesine olanak tanır.
- Aşırı Uyumluluk Sorunu: Random Forest algoritması, aşırı uyumluluk sorunu gibi sorunları minimize eder. Aşırı uyumluluk, bir modelin eğitim verilerine çok fazla uygun olması ve gerçek dünya verileri için kötü performans sergilemesi anlamına gelir. Random Forest algoritması, birden fazla karar ağacı kullanarak, her bir ağacın farklı bir şekilde eğitilmesi ve verilerin farklı bir şekilde bölünmesi nedeniyle aşırı uyumluluk sorununu önler.
